If you’re a programmer, you’ll hopefully be familiar with the difference between making a copy of an object and making a reference (or a pointer) to it. The former duplicates the data, resulting in two independent instances. The latter allows the same original data to be accessed in two different ways. These concepts are common to many languages, and are essential to passing and returning data in your program.
As of C++11, you can think of “move” as being a third alternative. It’s expanded the core features of the language, adding move constructors and move-assign operators to your class design arsenal. It’s required the introduction of a new type of reference as well, known as “R-value references”, which we’ll look at later.
To quote from Scott Meyers’ excellent C++11 training materials, “move is an optimization of copy”. In practical terms it’s very similar to copying, but can offer a number of advantages, especially where copying and referencing are impossible or undesirable. In this post, I’ll try to cover the basics of move operations so you can understand what they are and how you can start using them yourself.
Moving = transferring state / ownership
A bit of a mental hurdle to get over is what “move” really means. The program isn’t physically relocating any data. Rather, it’s transferring the state of one object into another. Think of it like selling a house. The building itself doesn’t get relocated or copied, but ownership transfers from the seller to the buyer.
In the same way, the state being transferred between objects in C++ could be ownership of a resource, such as a block of heap memory. The following diagrams illustrate the difference between a conventional deep copy and a move:
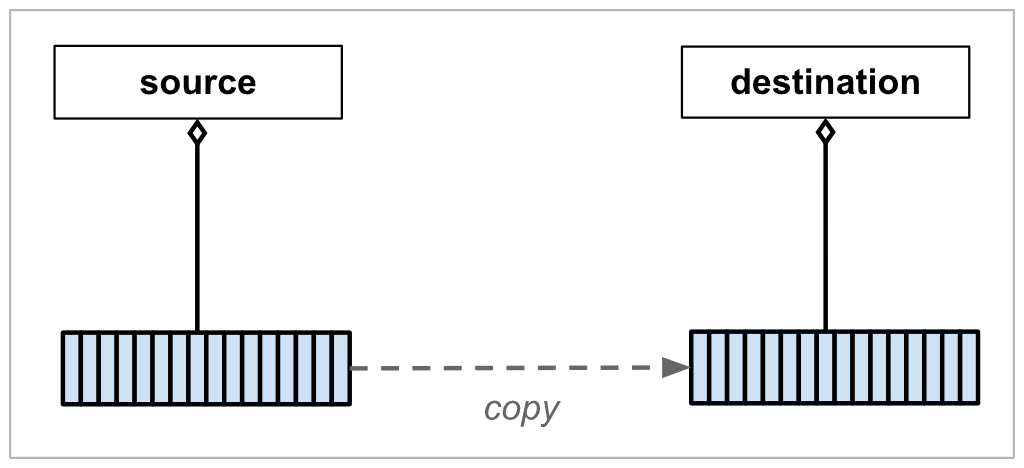
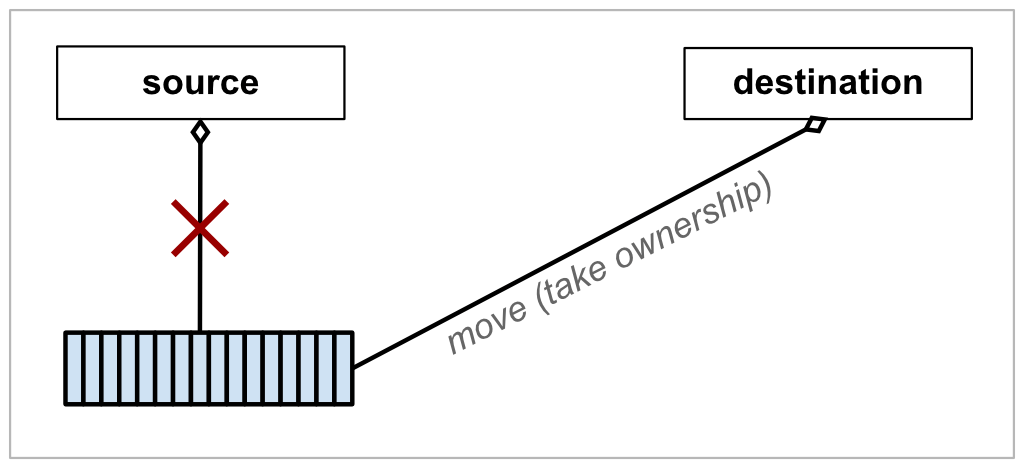
As with copying, you still have two instances of your containing class; i.e. the source object and the destination object (or the seller and buyer, to use our house-selling analogy). When the move occurs, the destination object is the one which does the processing. It releases its own state if necessary, acquires the source’s state, and then leaves the source object empty.
Note that the “state” being transferred could be anything, depending on your program. Transferring ownership of something on the heap is a common situation though.
Example
For this example, we’ll use the well known std::list container. The movable state is ownership of the nodes which contain the contents of the list.
Imagine you’re creating a parser class which is going to store and operate on a list of strings. The list will be provided by the caller, but our parser needs to be able to modify the list as it goes along. For example, it may need to remove elements as it processes them. We’ll provide two accessor methods to specify the list of strings: one to copy them over the old fashioned way, and one to move them across. If implemented correctly, move can be more efficient.
Everything except our accessors and member variable is omitted here for brevity:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class Parser
{
public:
// -- snip --
// Copy a list of strings into the parser
void setTokens(const std::list<std::string> & toks)
{
m_tokens = toks;
}
// Move a list of strings into the parser
void setTokens(std::list<std::string> && toks)
{
m_tokens = std::move(toks);
}
private:
// The list of strings we're going to operate on
std::list<std::string> m_tokens;
};
The move version of setTokens() takes a non-const R-value reference. This is indicated by the double ampersand (&&). This kind of parameter indicates that it’s safe to move data out of it. We’ll cover that more later.
Our parser class is now ready to receive moves, but that’s not the complete picture. You also need to make sure the calling code allows the move. This is what it might look like:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
void main()
{
// Populate a list with strings
std::list<std::string> tokens;
tokens.push_back("blah");
tokens.push_back("foo");
tokens.push_back("random-stuff");
tokens.push_back("arbitrary-string-data");
// Move the strings to the parser
Parser p;
p.setTokens(std::move(tokens));
// -- snip --
}
As you can see, we can construct and populate the list locally as normal. The only unfamiliar part of this is the use of std::move(). It tells the compiler that we’re expecting data to be moved out of it. If you omit this, the data will be copied instead of moved.
It’s important to note that the our local tokens list (in main()) will be empty after the setTokens() call. This is because ownership of all its nodes will have been transferred into Parser::m_tokens. Technically, you can continue to use the local tokens list after the move has happened because it will be left in a valid empty state. I’d typically advise against that though as it could make your code confusing.
Side note: As usual, the above example is somewhat contrived. In practice, you shouldn’t usually need to define separate copy and move versions of the same function (except for constructors and assignment operators). Best practice is usually to define a single function which takes the parameter by value, and then move the data from the parameter to the class member.
R-value references
R-value references are a new feature in C++11. They are designed primarily to enable move semantics, and are denoted by a double ampersand (&&). They are named “R-value” because they represent things you would see on the Right hand side of an assignment. That is, something you can assign from but cannot assign to. Conventional references are now known as “L-value” references because they represent things you can assign to. That is, they can appear on the Left hand side of an assignment as well as the right. As a side note, the “L-value” / “R-value” terminology actually goes back to the early days of C. It’s the idea of a reference to an R-value which is new.
As I mentioned above, the idea of an R-value reference in this context is that it tells you it’s safe to move data out of the object. An important consequence of this is that your R-value references need to be mutable (non-const). This is because a move operation needs to modify the source to leave it empty. If the source is const then you can’t move anything out of it.
Implicit moves
There are situations where the compiler will attempt a move implicitly, meaning you don’t have to use std::move(). This can only happen if a non-const movable object is being passed, returned, or assigned by value, and is about to be destroyed automatically.
This imminent destruction of the source object is vital. If the source object will exist after the move then the compiler may not be able to guarantee that you won’t try to access it again later. When you use std::move() to invoke an explicit move, you’re overriding this check.
An implicit move will often happen where the source object is temporary, e.g. when it’s instantiated inline. For example:
1
2
3
4
5
6
7
8
std::list<Widget> data;
// Temporary object will be implicitly moved into list:
data.push_back(Widget(123));
// Non-temporary object won't be implicitly moved:
Widget w(123);
data.push_back(w);
An imminent destruction can also happen where you’re returning a local variable. For example, let’s say you’ve written a function to create and return a list of any size, filled with random integers. If it creates the list locally then it will be destroyed as soon as the return statement is finished:
1
2
3
4
5
6
std::list<int> makeRandomList(int size)
{
std::list<int> data(size);
std::generate(data.begin(), data.end(), std::rand);
return data;
}
It’s worth noting that implicit moves aren’t guaranteed. There are situations where the compiler will find a better optimisation, such as copy elision. As with any optimisation though, the exact behaviour may vary depending on your compiler and its configuration.
Making a class movable
Implementing move semantics on your own classes is fairly simple. You’ll typically need to define a move constructor, and possibly a move assignment operator. The move constructor just transfers things in, and leaves the source object empty. However, the move assignment operator may need to release the destination’s existing data before moving anything in.
For this example, let’s imagine you’re making your own dynamic array class. To keep things simple, we’ll hard-code it to be an array of ints. It has two member variables: an unsigned integer called m_count, which specifies the number of elements in the array, and m_data which is a pointer to the array data on the heap.
Your move constructor could be implemented like this:
1
2
3
4
5
6
7
8
9
// Move constructor
MyArray::MyArray(MyArray && rhs) :
m_count(rhs.m_count),
m_data(rhs.m_data)
{
// Leave the source empty
rhs.m_count = 0;
rhs.m_data = nullptr;
}
This looks much like a copy constructor at first. The initialisation does a member-wise copy from the source object, but crucially it’s a shallow copy. This means it copies the address of the m_data pointer but not the data itself. It then resets the source object’s members to a valid but empty state. As a result, the newly constructed object is now responsible for the heap memory.
A quick side note about
nullptr: It’s another new feature of C++11 which provides a safe and standardised way to specify a null pointer. It works for any pointer type, and I strongly recommend using it in place of of the conventionalNULLmacro or number 0.
Our move assignment operator follows a similar pattern to our move constructor:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// Move assignment operator
MyArray & MyArray::operator = (MyArray &&rhs)
{
// Delete any existing data
delete m_data;
// Copy state from the source
m_count = rhs.m_count;
m_data = rhs.m_data;
// Leave the source empty
rhs.m_count = 0;
rhs.m_data = nullptr;
return *this;
}
Aside from the fact that assignment operators don’t have initialisation lists, the only difference from the move constructor is the delete statement. The destination object (i.e. the one you are moving to) may already own some data. As such, we have to clear it up safely otherwise we’ll end up with a memory leak.
You may be wondering why we’ve got a move constructor and a move assignment operator even though they’re very similar. Much like copy construction / assignment, there will be many situations where you want to move-construct, and some situations where you want to move-assign.
As a general rule, if you want to make a class movable then always start by defining a move constructor. If your class can have data moved into it after construction, then give it a move assignment operator as well. It’s often acceptable to make the move constructor call the move assignment operator. Sometimes it’s more efficient to define them separately though.
The move-to-self trap
For simplicity, I haven’t included a check for move-to-self in the examples above. However, consider the following situation:
1
data = std::move(data);
The source and destination of this move are the same object. This potentially leads to a serious problem: it could end up releasing the resource it is trying to move. You can resolve this by putting a check at the top of your move assignment operator. Something like this is typical:
1
if (this == &rhs) return *this;
This isn’t necessary in the move constructor because you can’t move from something which hasn’t been instantiated yet.
Semantics and good practice
You might look at the idea of passing-by-value (instead of reference) and immediately gawk at how bad practice it is. Remember though that it’s only considered bad practice because of how costly a deep-copy can be. If we take that issue away then the reason for pass-by-reference is considerably reduced.
Also consider the semantics of pass-by-reference. If you make a function take a reference, you’re effectively saying “this function needs to refer to the original object”. In reality, that’s not very common. A function usually just needs to operate on whatever data it’s given, so pass-by-value could be considered more ‘correct’ from a certain point-of-view.
Moving is still more of an overhead than passing a const reference though. As such, you’ve got to balance semantic correctness against performance. The right choice depends on your program, your coding style, and whatever conventions you have to follow.
Conclusion
We’ve taken a fairly simple look at some of the basics of move semantics, and hopefully covered what you need to get started using moves in your own code. I’ve stuck with fairly simple heap data moves here for my examples. However, moves can be helpful for many other transfers of ownership.
For example, if your class is designed to manage exclusive access to a device then you don’t want to accidentally end up with multiple copies all trying to control it. In this situation, a move could be helpful in making sure only one instance at a time actually owns the resource.
I’ve also touched on the topic of R-value references. These offer some interesting new opportunities for your set of C++ coding techniques. I recommend reading-up further on them as you explore move semantics in your own code. An interesting (but quite advanced) area you might like to explore is what Scott Meyers has termed “universal references”.